Unlocking Author-Affiliation Metadata for All of arXiv
The COMET team is pleased to share results from an exciting line of work we have recently completed, focused on unlocking author-affiliation metadata from preprints. Specifically, we have trained a small, open-weight large language model (LLM) that achieves state-of-the-art performance on author-affiliation extraction for arXiv works. With this approach, we have for the first time produced open author-affiliation metadata for the full arXiv corpus as of December 2025, enabling community use and allowing for direct improvements to persistent identifier metadata. The trained model and dataset are openly available and free to use. Please read on to learn more!
Preprints Outpacing their Metadata
Rapid research dissemination has become central to modern scientific practice. The rate of preprinting has risen dramatically in recent years , with preprints themselves now viewed as a first-class output in many fields. These trends have only been accelerated by major funders, often encouraging or mandating preprint deposition. However, the speed and openness of preprinting has, to date, come with tradeoffs for the completeness of their metadata. A recent analysis by Nees Van Eck and Ludo Waltman details the scale of this gap, finding that many major preprint servers fail to deposit basic elements such as author affiliations, ORCID IDs, funding information, or abstracts.
Why do these metadata gaps exist? Historically, producing high-quality persistent identifier metadata has demanded considerable expertise, manual review and collection, and management of complex data flows across systems. This resource-intensive, ongoing process requires significant investment from publishers and bibliometric systems. Preprint venues, by contrast, have often lacked the same resources necessary to complete this work, particularly given the scale of their backlogs requiring more complete description.
These gaps in preprint metadata produce a real contradiction. Researchers are advancing the pace of science through preprints, yet this impact is understated because preprint metadata often lacks important elements like the affiliation details needed to link these works to their authors and institutions. Even where more complete accounts of impact claim to exist, such as in proprietary bibliometric tools, we have limited visibility into how those metrics were produced or how reliably they reflect the underlying record. The implications for research assessment are stark. To paraphrase a rallying cry of the Barcelona Declaration: how can we fairly evaluate the contributions of researchers and institutions if the underlying metadata is incomplete or the product of opaque, closed systems?
Open, Community-Driven Enrichment
The answer is to extend the same principle. Researchers have moved to preprints to take ownership of how their work is shared. Now the community has an opportunity to do the same for metadata, producing it openly, at its source in persistent identifier infrastructures, to a standard that rivals what closed venues and systems offer. This means building new pathways for metadata improvement that are transparent, comprehensible to all, and to which all stakeholders can contribute.
This is precisely why we organized COMET, to bring the community together and improve metadata directly in open infrastructures. Building on prior work with both arXiv and DataCite (where arXiv registers its DOIs), we set an ambitious goal: bring the affiliation metadata for arXiv preprints up to the standard the research community expects from traditional publishers and closed bibliometric tools, so that preprinted research can be discovered, assessed, and attributed with the same confidence as traditionally published work.
Affiliation Extraction for arXiv
Achieving these ambitions was, as always, easier said than done. Unlike our prior work on arXiv preprint matching, which linked one existing description to another using structured publication metadata, affiliation metadata is typically locked inside the full text. Extracting authors and affiliations from full-text sources is not straightforward, as these details are not always found in a consistent location. Authors and affiliations can span across multiple pages, appear in footnotes, or be found only on the last page of a work.
Likewise, no existing high-quality datasets were available to benchmark performance on this task for arXiv. Our first step was to create one. To do so, we extracted a random sample of over 2,000 works from all of arXiv and manually reviewed and annotated them, identifying authors and linking them to their affiliations through multiple rounds of human and automated correction. This benchmark is now available as an open dataset, allowing anyone to empirically evaluate any method for this task.
With this new benchmark in hand, the next step was to assess how existing author and affiliation extraction tools perform against it. We began by evaluating GROBID, a widely-used, open-source tool for extracting structured metadata like authors, affiliations, and references from PDFs. While GROBID performed well on author extraction for arXiv works, it underperformed on affiliation extraction, achieving only about 80% precision and 50% recall, even using a lenient form of evaluation that counted an assertion as valid based on fuzzy string matching. For our purposes of deriving high-quality author-affiliation metadata, these results were deemed insufficient.
We then evaluated structured extraction using large closed models, such as Anthropic's Claude, to establish a performance ceiling representing the frontier of what is technically possible for LLMs. What we also found was that while these models performed quite well and could handle full-document extraction (necessary here, again, because affiliation information can appear anywhere in the preprint), using them across arXiv's nearly 3 million works would cost an estimated $60,000–$100,000 for these large inputs. Beyond cost, this approach, again, produces no durable or reusable artifacts and runs counter to COMET's aim of building free, open-source, and reproducible enrichment workflows, making it fundamentally unsustainable for ongoing work.
Fine-Tuning a Small Open-Weight Model
Given these findings, the approach we aligned on was to fine-tune a small, open-weight language model specifically for our task. We hypothesized that a smaller, task-specific model could approach the performance of larger models while being far more practical to deploy. A smaller model would also enable faster and more memory-efficient inference on long-context inputs, as fewer computations are required for a smaller model to generate each output.
Training Methodology
After evaluating different training methods, we found that off-policy distillation yielded the best results. In practical terms, this means we used a large open-weight "teacher" model to produce author and affiliation extractions along with its reasoning traces, the intermediate steps leading to each output. We retained only those outputs where the extraction was correct, then used them as high-quality training examples to fine-tune a smaller "student" model to learn the same task.
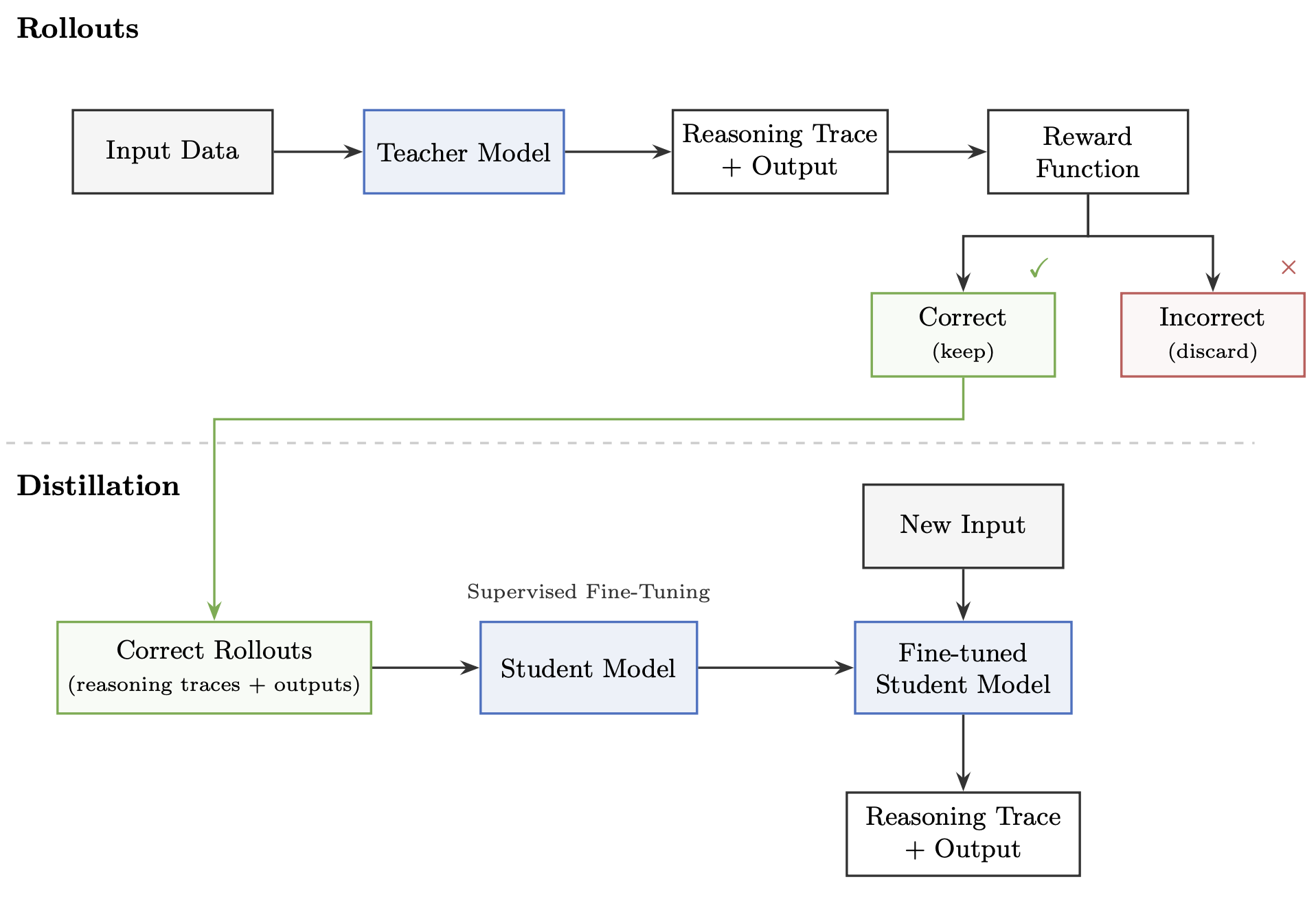
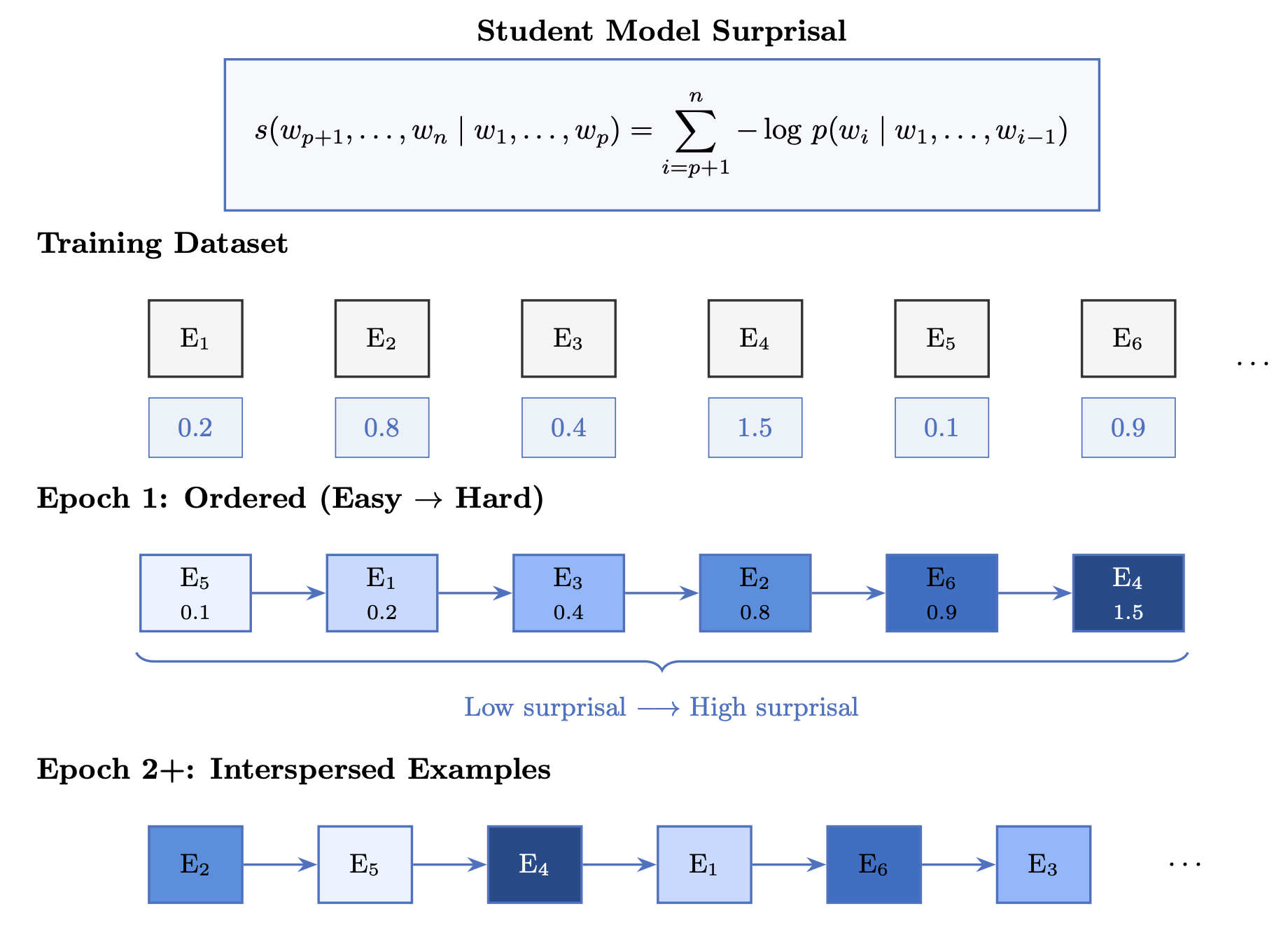
We ordered the training examples according to a curriculum. Using the student model's surprisal, a measure of how unlikely each example is based on the model's current predictions, we began training with more straightforward examples and gradually introduced harder ones, interspersing both throughout later rounds to reinforce prior learning.
Results
Through testing of a number of open-weight teacher-student model pairs, we found the best result came from distilling GLM-4.5-Air into Qwen3-8B. This combination, using our training regime, achieved 97% precision and 86% recall for authors, and 91% precision and 81% recall for affiliations. This performance approaches that of closed models in our benchmarks, while yielding an enrichment workflow the community can actually use, inspect, and build upon.
Large-Scale Inference and Affiliation Matching
With these results in hand, we conducted large-scale inference on a markdown conversion of the full arXiv corpus as of December 2025. From approximately 2.8 million works, we extracted 10.3 million author entries and 12.1 million affiliation entries. Using an affiliation matching strategy designed by Crossref's Director of Technology, Dominika Tkaczyk, we matched 9.2 million of those affiliations to ROR IDs, or 76% of the total, with the matching strategy known to perform at approximately 97% precision. Combined with DataCite metadata, these two interventions for the first time provide the foundation for truly open, reproducible impact tracking and institutional monitoring across the entirety of arXiv.
What's Next
Looking ahead, we are applying similar methods to train models for extracting additional metadata, such as references, dataset citations, and similar fields. We are also building workflows for reconciling our author and affiliation extractions and ROR ID assignments against parallel community assertions, recognizing that no single method is perfect or can address all edge cases. Because our models and methods are open, they can also be adapted for use in other preprint servers. We welcome collaborators who want to build on or contribute to this work!
Concurrently, DataCite is building a metadata layer for integrating community enrichments alongside member-submitted metadata, enabling the data COMET produces to flow back out to everyone harvesting from their APIs and data files. DataCite is actively seeking feedback on this work. Please review and contribute to the discussion here: https://github.com/datacite/datacite-suggestions/discussions/209.
Build With Us
The code, datasets, and models for this project are all open source, available on our GitHub and HuggingFace accounts. We view this work as capacity building toward COMET's broader goal of working with the community to enrich metadata at its source in infrastructures, so researchers and institutions can see themselves fully reflected in the scholarly record. If you see opportunities to make use of it in your local context, whether through direct application, further development, or the creation of new benchmarks, or would like to collaborate with us on similar efforts, please do not hesitate to reach out.